为什么百度不会收录你的网站?

新网站而言更重要的是比不被百度索引麻烦吗?本文旨在帮助您创建一个百度一般理由不能索引你的网站。
如何检查百度网站指数如果你想开始确定您的web页面(可能是所有网站)不是在百度索引请安排如下:
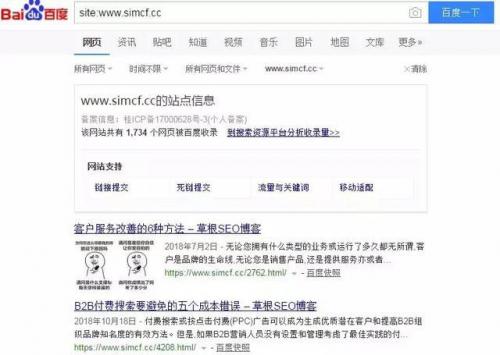
1。使用“网站:ww.simcf。cc”查询公司请安排如下:
1。使用“网站:ww.simcf。cc”查询这将显示近似URL为域百度索引的搜索引擎如下图所示:
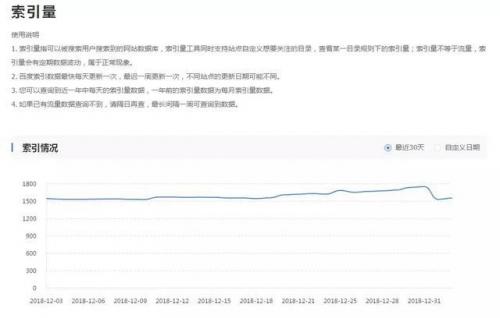
2。登录到百度站长控制平台和去索引卷检查近似的URL。索引的数量如下图所示:
9常见原因百度不包括网站代码除了1.200
共识如果页面没有共识的200台服务器然后不?t期望搜索引擎将它们索引(可能保护指数如果他们已经索引)。偶尔URL将被重定向意外500 404 0 r的缺点将打破。它只是一个CMS服务器问题或用户的缺点。请检查它迅速确保准确加载页面的URL。
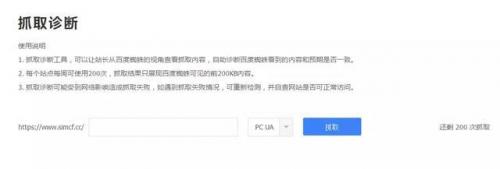
2.机器人。三种检查
/机器人。txt文件的网站(美国现状位于网站的根目录)为百度提供爬行命令。如果某个网页在网站上不被百度索引那么机器人。txt文件的第一次检查。如果你想检查网址是否被机器人。txt文件请跳到百度站长平台控制尝试“爬行和调整”如下
3。“Noindex meta-machine标签
某个页面在网站上另一个常见的原因可能不是在百度索引可能是机器有一个“Noindex元标记的页面。当百度看着这个meta-machine标签这是一个准确的声明它不应该被用作索引页面。毕竟百度会尊重这个命令它可能有各种各样的方法这只是取决于其编码方法:
下面是实际的页面截图:

检查页面是否有“noindex元机人马克请看源代码并找到它的代码。如果网站使用java出发你可能需要使用Google Chrome的“检查元素”功能准确地检查。
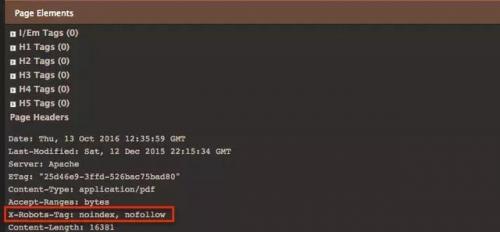
4。“Noindex X-Robots标记
像meta-machine X-Robots标记提供了控制百度指数的函数通过页面级标签。然而这个标签是用于某个特定页面的标题的共识或文档。它通常用于html页面比如PDF文件DOC文件和其他文件网站控制器渴望离开百度指数。“noindex”X-robots标签不太可能出乎意料但您可能希望使用SEO站点工具扩张一步具体的铬检查出来。如下:
5。大量重复
大量重复是所有SEO服务的风险。重复的物质可能会导致您的web页面离开百度指数。如果重复的网页上物质的速率大可能不好。如果有特定的网页在您的网站上似乎是显而易见的这可能是因为你没有被百度索引的网页(例如集合的10英尺站点会特别慢)。
6。完整的索引可能缺乏价格
特定页面和网站都非常贫穷所以它不能提供足够的百度指数的价格。例如只有一个联盟网站的理想自然忏悔不付出代价的用户。百度已经纠正其算法停止排名(和偶尔索引)这类网站。
7。网站仍然是新的和无证
新网站不会被百度等搜索引擎索引尽快。它需要链接和其他旗帜让百度索引网站在搜索的最后期限。和排名(看一看)。这就是为什么建立链接网络只有一个联盟网站的理想自然忏悔不付出代价的用户。百度已经纠正其算法停止排名(和偶尔索引)这类网站。
7。网站仍然是新的和无证
新网站不会被百度等搜索引擎索引尽快。它需要链接和其他旗帜让百度索引网站在搜索的最后期限。和排名(看一看)。这就是为什么建立链接因为新网站是如此重要。对于刚刚推出的网站最好是直接问百度链接上网后通常安排在一小时内网站主页。
8。页面加载时间
如果网页逐渐加载并没有恢复百度可能会降低其排名随着时间的流逝和甚至可能从索引中删除的网页搜索引擎。通常索引卷将很低。
9。孤儿页面
百度将爬行你的网站(和XML站点地图)找到这种物质的链接更新其索引提高网站的排名在搜索截止日期(和其他因素)。如果百度找不到实际的链接你的网站或外部网站网络提高网站的排名在搜索截止日期(和其他因素)。如果百度找不到实际的链接你的网站或外部网站百度不会让这些链接所以它不会被索引。