Presto查询引擎简单分析
每个组件的角色UI(用户界面):窗口提交数据操作
司机(引擎):负责接收数据操作实现会话处理并提供JDBC / ODBC-based执行和获取API
Metastore(元数据):蜂巢的元数据已更新并提供JDBC / ODBC-based执行和获取API
Metastore(元数据):蜂巢的元数据存储所有表信息和相关HDFS文件存储目录通常使用MySQL或derby存储
编译器(编译器):解析SQL查询生成一个阶段性执行计划(包括元数据操作MapReduce)
执行引擎(执行引擎):执行编译器生成的执行计划。DAG的执行计划是一个阶段
查询过程步骤1:驱动程序的执行界面调用UI
步骤2:驱动程序创建一个会话处理查询并将查询发送给编译器生成执行计划
步骤34:编译器获取相关元数据metastore
第五步:检查元数据调整分区基于查询谓词解析SQL并生成执行计划
步骤66.16.26.3:执行计划由编译器生成了DAG。每个阶段涉及到Map / Reduce作业元数据操作或HDFS文件操作。
在Map / Reduce阶段执行计划包括地图操作树(上执行操作树映射器)和减少操作树树(Reduce操作执行还原剂)
执行引擎提交每个阶段为执行一个适当的组件。
步骤78和9:在每个任务(映射器/减速机)相关的表或中间输出反序列化器读取行从HDFS并将它们传递到相关操作树。
一旦这些输出生成零时HDFS文件将生成通过序列化器(这只发生在只有地图没有减少)和生成的HDFS零时文件用于随后的Map / reduce阶段的执行计划。
DML操作临时文件终于搬到表的位置。这个解决方案可以确保没有读脏数据(在HDFS文件重命名是一个原子操作)查询
临时文件的内容直接读取HDFS执行引擎作为司机取回API的一部分
转眼间查询流程分析
实现Map / Reduce阶段?计划包括地图操作树树操作执行映射器吗?和减少
每个组件的角色客户:提交数据操作的窗口
发现服务器(服务发现者):存储可用服务器列表
协调员(协调):接收数据操作解析SQL语句生成查询计划和任务分发给工人的机器
连接器插件:连接Storagr关键词和任务分发给工人的机器
连接器插件:连接Storagr提供元数据支持蜂巢卡夫卡MySQL MonogoDB复述JMX和其他数据源可以定制
工人(执行者):执行查询计划
查询过程1。客户端发送一个查询请求使用HTTP协议
2发现可用的服务器通过发现服务器
3构建一个查询计划协调员(解析成通过Anltr3 AST(抽象语法树)关键词构建一个查询计划协调员(解析成通过Anltr3 AST(抽象语法树)然后获得原始数据的元数据信息通过连接器生成分配计划和执行计划)
4。协调员将任务发送给工人
5工人通过读取数据连接器插件
6工人在内存中执行任务(工人是一个纯内存计算引擎)
7工人返回数据协调员聚合反应后客户端很快和蜂巢
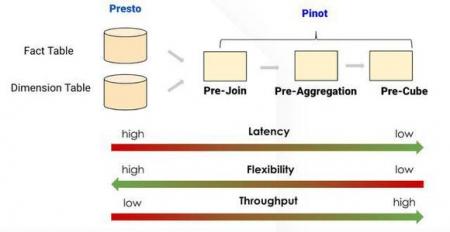
比较区别:
MapReduce对于每个操作需要写入磁盘和每个阶段需要等待前一个阶段完成之前开始执行。
转眼间SQL转换阶段。一个阶段是执行多个任务每个任务分为多个分裂。
所有任务并行执行执行阶段之间的数据流的形式管道
传输的数据也进行内存到内存的形式通过网络没有磁盘io操作。
这也是很快的性能的决定性原因是5 - 10倍蜂巢
转眼间缺点
1。没有容错。当分布到多个工人执行查询当一个工人无法查询出于各种原因主感知后整个查询将失败
2。内存限制。因为很快是一个纯内存计算当内存不够转眼间不会结果转储到磁盘所以查询将失败(据说很快的最新版本已经支持磁盘写操作)
3。并行查询因为所有任务并行执行如果其中一个工人非常缓慢出于各种原因那么整个查询将变得很慢
4。并发性限制。